
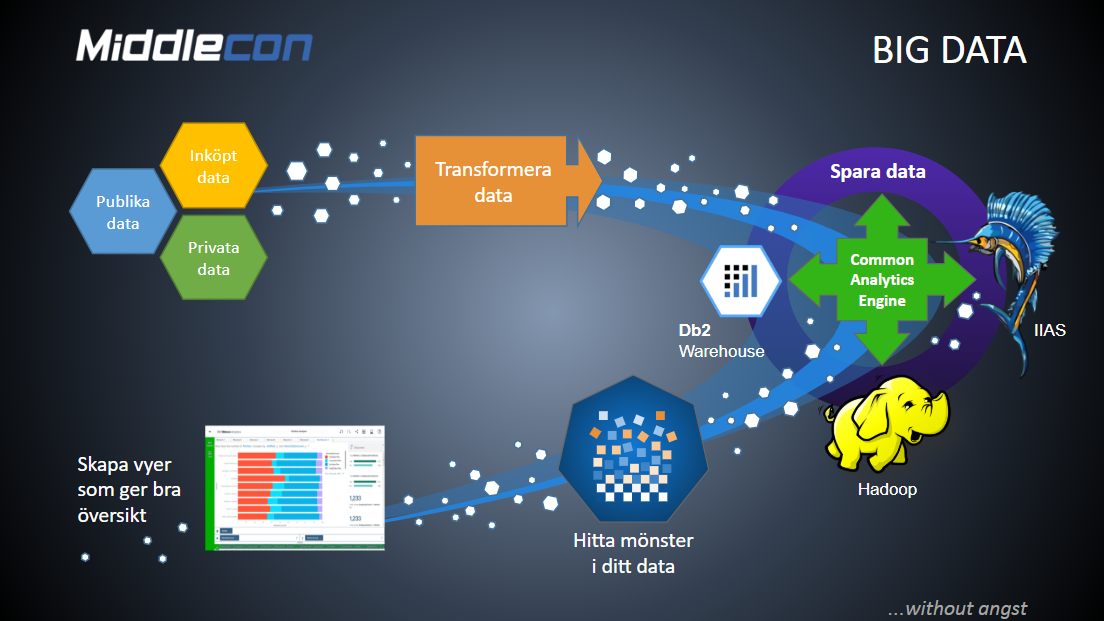
För dig som är ny inom big data kan det vara bra att veta att det finns tre typer av data:
- Data som du själv äger, med andra ord privata data t ex ekonomisystemets data
- Data som du köper in, alltså inköpt data som t ex väderdata
- Data som är fritt tillgängligt, det vill säga publika data t ex från Statistiska Centralbyrån
Alla dessa data ser ut på olika sätt. Ditt ekonomisystem kanske exempelvis har ett svenskt datumformat, medan Twitter har ett amerikanskt datumformat.
Om du vill ställa en fråga mot detta data senare är det bra att transportera och göra om det innan du lagrar denna data på ett sätt som fyller dina syften. I vissa fall behöver du svar snabbt, i andra fall vill du ha en så låg kostnad per TB som möjligt. Utifrån dina önskemål så väljer du t ex Hadoop, IIAS (Sailfish) eller en vanlig Db2 databas.
Genom att använda Common SQL Engine behöver du inte anpassa din SQL till dessa olika plattformer, utan kan utnyttja den SQL du har oavsett plattform. Common SQL Engine stöder förutom IBM även konkurrenters plattformer såväl som open source plattformer.
Väljer du denna teknik så underlättar du för data scientists som skall hitta samband, och för de som senare skall bygga rapporter mot data. Har du en AI som behöver tillgång till data så kan även den med fördel använda Common SQL Engine.
Les King var med oss på Data Server Day och berättade bland annat om detta verktyg. Kolla filmklippet nedan för att se hans introduktion till Common SQL Engine.
https://www.youtube.com/watch?v=1pRzO-JytdI[:]


